Twój wynik: Informatyka Stosowana
Analiza
Wszystkie ({{dataStorage.userResults.answersTotal}})
Prawidłowe ({{dataStorage.userResults.answersGood}})
Do powtórki ({{dataStorage.userResults.answersRepeat}})
Błędne ({{dataStorage.userResults.answersBad}})
Pytanie 1
W systemie Linux dostępne są następujące algorytmy szeregowania zadań
statyczne FIFO i Round Robin i dynamiczny SCHED_OTHER
statyczny FIFO i dynamiczne SCHED_OTHER i Round Robin
statyczny SCHED_OTHER i dynamiczny FIFO
statyczny SCHED_OTHER i dynamiczne FIFO i Round Robin
Pytanie 2
Jest prawdą, że w systemie Linux szeregowaniu zadań w trybie dynamicznym pierwsze zadanie do wykonania to:
zadanie o największej wartości nice,
b) zadanie, które ma najwięcej niewykorzystanych impulsów zegara w bieżącej epoce,
c) zadanie o najwyższym priorytecie dynamicznym,
d) które ma największą wartość atrybutu interactive credit,
Pytanie 3
Prawdą jest, że szeregowanie procesów w systemie Linux cechuje następująca własność:
d) zadania o priorytecie statycznym podlegają wywłaszczeniu.
a) wyznaczanie epoki następuje po zakończeniu wykonywania procesów czasu rzeczywistego,
c) istnieje wsparcie dla aplikacji interaktywnych, które wykorzystuje sygnały od klawiatury i myszki M
b) w pierwszej kolejności w zakresie dynamicznym wykonywane są procesy zgodnie z regułą SJF,
Pytanie 4
Prawdziwy jest następujący opis dotyczący zasad szeregowania zadań w systemie
Windows NT:
c) połowa niewykorzystanego czasu jest dodawana przy następnym uzyskaniu procesora,
a) aplikacje pierwszoplanowe mają priorytet 15,
b) doładowanie podnosi priorytet procesom serwerowym, oczekującym na dostęp do HDD,
jeśli proces wykorzystał swój przedział czasowy, to obniżana jest wartość jego priorytetu o 1,
Pytanie 5
Prawdziwy jest następujący opis dotyczący zasad szeregowania zadań w systemie
Windows NT:
b) proces w tle może mieć krótszy czas wykonania niż procesy aktywne,
d) proces, który wykonał się poprzez przydzielony czas procesora ma skracany czas wykonania w następnym przedziale.
a) Procesy serwerowe mają dwa razy dłuższe czasy wykonania niż procesy w tle,
c) proces interaktywny jest wspierany przez mechanizm ochrony przed zagłodzeniem,
Pytanie 6
Prawdziwy jest następujący opis dotyczący zasad szeregowania zadań w systemie
Windows NT:
b) procesy, które mają niższy priorytet niż aktualnie wykonujące się, muszą czekać na zakończenie wykonywania procesów o wyższych priorytetach,
c) proces, który dostał zasób, na który czekał, dostaje jednorazowo priorytet 15,
d) procesy serwerowe w systemach serwerowych mają dłuższe przedziały wykonywania. M
a) procesy, które mają wyższy priorytet czekają na zakończenie aktualnie wykonującego się procesu, a następnie dostają zasób procesora,
Pytanie 7
Prawdziwy jest następujący opis dotyczący poziomów priorytetów w systemie
Linux:
wartość priorytetu dynamicznego zależy od programisty, M
b) priorytet statyczny jest zmieniany w trakcie wykonywania programu przez system operacyjny,
d) wartość priorytetu statycznego wpływa na liczbę impulsów, w oparciu o które wyznaczany jest czas wykonywania się.
a) w systemie Linux procesom nadawane są priorytety statyczne, dynamiczne i mieszane,
Pytanie 8
Prawdziwy jest następujący opis dotyczący poziomów priorytetów w systemie
Linux:
priorytet dynamiczny można zmieniać komendą nice,
b) priorytet statyczny można zmieniać komendą nice,
d) wartość interactive credit pozwala na zmianę z linii poleceń priorytetów dynamicznych
a) priorytet dynamiczny jest realizowany dla procesów o priorytecie statycznym równym 99,
Pytanie 9
Prawdziwy jest następujący opis dotyczący poziomów priorytetów w systemie
Linux:
c) parametry interactive credit i nice mogą być zmieniane z linii poleceń lub programowo,
d) jako pierwszy do wykonania wśród procesów dynamicznych zostanie wybrany proces o największej przydzielonej liczbie impulsów zegara.
a) czas wykonywania na procesorze jest obliczany w oparciu o priorytety statyczny i dynamiczny,
b) czas wykonywania na procesorze jest obliczany w oparciu o priorytety statyczny i wartość nice,
Pytanie 10
Prawdziwy jest następujący opis dotyczący poziomów priorytetów w systemie
Windows NT:
c) aplikacja aktywna ma podwyższony priorytet na 15.
b) priorytet może być zmieniany dynamicznie w zakresie 0-31
a) tylko wybrane wartości priorytetu w zakresie 16-31 mogą być osiągnięte
c) aplikacje serwerowe mają priorytet równy priorytetowi zadań systemowych (11)
Pytanie 11
Prawdziwy jest następujący opis dotyczący poziomów priorytetów w systemie
Windows NT:
wątek procesu o klasie HIGH z modyfikacją THREAD_PRIORITY_IDLE jest mniej ważny niż wątki procesu NORMAL bez modyfikacji.
b) procesy w klasie NORMAL mają priorytet 8, a w klasie HIGH - 11,
a) każdemu wątkowi po przydzieleniu THREAD_PRIORITY_TIME_CRITICAL zostaje nadany priorytet 15,
c) procesy w klasie NORMAL nie mogą osiągnąć priorytetów wątków 15,
Pytanie 12
Prawdziwy jest następujący opis dotyczący poziomów priorytetów w systemie
Windows NT:
d) danemu wątkowi można programowo zmienić klasę procesu.
a) klasy procesów można przypisywać wątkom danego procesu,
b) wartość klasy procesu można modyfikować w trakcie wykonywania procesu,
c) wartości modyfikatorów priorytetów wątków dotyczą też klas procesów,
Pytanie 13
Prawdziwe jest określenie dotyczące szeregowania wieloprocesorowego w systemach Linux i Windows NT:
c) w obu systemach można przydzielać wybrane zadanie do wybranego procesora,
a) w systemie Windows są osobne kolejki do każdego procesora,
d) w systemie Linux jeden z procesorów służy do obsługi głównie procesów zagłodzonych
b) w systemie Linux jest jedna kolejka do każdego procesora, M
Pytanie 14
Prawdziwe jest określenie dotyczące szeregowania wieloprocesorowego w systemach Linux i Windows NT:
c) jeśli różnica w planowanym wykonaniu dla danego procesora jest większa niż 20% w stosunku do innego procesora, Windows przerzuca wykonanie zadań na ów procesor,
d) równoległe wykonywanie zadań jest w systemie Linux bezpośrednio powiązane ze wsparciem aplikacji interaktywnych.
b) w systemie Windows są osobne kolejki do każdego procesora, a ostatni obsługuje tylko procesy zagłodzone,
a) w systemie Linux są osobne kolejki do każdego procesora,
Pytanie 15
Prawdziwe jest określenie dotyczące szeregowania wieloprocesorowego w systemach Linux i Windows NT:
a) W systemie Windows kolejki zadań do wykonania na procesorach są wyznaczane w każdej epoce,
c) system Linux dla danej kolejki zadań obniża czas wykonania o połowę jeśli długość planowanych zadań przekracza 20% kolejki zadań dla pozostałych procesorów,
d) system Windows w sposób płynny równoważy obciążenie dla kolejek do procesorów skracając przydziały czasu procesora.
b) system Linux przesuwa część zadań do wykonania na inny procesor, jeśli różnica planowanego obciążenia wynosi 25%,
Pytanie 16
Prawdą jest, że:
d) zagłodzenie procesu w systemie Windows NT prowadzi do zawieszenia systemu.
a) zagłodzenie procesu jest wyraźnie zauważalne w przypadku procesów interaktywnych,
c) zagłodzenie procesu w systemie Linux powoduje wyraźny spadek wydajności systemu,
b) zagłodzenie procesu to długotrwałe oczekiwanie na semafor,
Pytanie 17
Prawdą jest, że:
a) zagłodzenie procesu dotyczy tylko procesów interaktywnych,
b) zagłodzeniu w systemie Windows NT odpowiada moduł obsługi systemu plików
d) w systemie Windows każdy oczekujący na CPU proces, który się od dłuższego czasu nie wykonuje, dostaje wysoki priorytet.
c) w systemie Linux zagłodzenie procesów nie występuje,
Pytanie 18
Prawdą jest, że:
b) w systemie Windows algorytm ochrony przed zagłodzeniem równomiernie podwyższa priorytety wszystkim procesom,
d) w systemie Windows procesy, które najdłużej się nie wykonywały są przydzielane do poszczególnych procesorów.
c) W systemie Linux niewykorzystane impulsy są częściowo przekazywane procesowi w nowej epoce,
a) W systemie Linux algorytm ochrony przed zagłodzeniem zwiększa priorytet statyczny,
Pytanie 19
Prawdą jest, że:
b) w systemie Windows procesy, które oczekują na klawiaturę i myszkę, mają wydłużany czas przydziału procesora,
d) aplikacje interaktywne często nie wykorzystują w pełni przydzielonego czasu procesora, co jest wykorzystywane przez algorytm ochrony przed zagłodzeniem do podwyższania priorytetu w Linux.
a) w systemie Linux wsparcie dla aplikacji interaktywnych oparte jest o większe priorytety procesów korzystających z myszki i klawiatury,
c) w systemie Linux wsparcie aplikacji interaktywnych odbywa się na takich samych zasadach jak w systemie WIndows NT, odpowiednio do modelu priorytetów danego systemu operacyjnego,
Pytanie 20
Prawdą jest, że:
a) wsparcie aplikacji interaktywnych w systemie Linux odbywa się tylko poprzez mechanizm ochrony przed zagłodzeniem,
b) system Windows NT wspiera aplikacje interaktywne poprzez przydzielenie priorytetu 15 i wydłużenie przydzielonego czasu procesora dla każdej aplikacji,
d) system Linux wspiera aplikacje korzystające z klawiatury i myszki
c) system Windows NT używa algorytmu doładowania dla klawiatury i myszki,
Pytanie 21
Prawdą jest, że:
a) Procesy interaktywne wymagają wydłużonego przedziału czasu procesora w Windows NT,
b) Procesy interaktywne oparte o konsolę nie wymagają wsparcia ze strony systemu Linux,
c) System Linux przerzuca wykonywanie procesów interaktywnych na najmniej aktualnie obciążony procesor,
d) System Windows wspiera doładowanie procesów oczekujących na zdarzenie z klawiatury bardziej niż oczekujące na zdarzenie z HDD.
Pytanie 22
Prawdą jest, że potoki anonimowe:
d) wymagają użycia dodatkowego mechanizmu do synchronizacji.
b) umożliwiają na komunikację dwóch niespokrewnionych procesów,
a) realizują przepływ danych ograniczony w przestrzeni adresowej jednego procesu,
c) realizują komunikację w pełni obustronną,
Pytanie 23
Prawdą jest, że potoki anonimowe:
b) umożliwiają komunikację między procesem odbierającym a procesem nadającym (twórcą potoku),
c) pozwalają na komunikację procesów niespokrewnionych ale tylko w obrębie jednej maszyny,
a) umożliwiają komunikację między procesem nadającym a procesem odbierającym (twórcą potoku),
d) pozwalają na komunikację między procesem macierzystym a procesem potomnym.
Pytanie 24
Prawdą jest, że:
d) pozwalają na komunikację w sieci.
a) potoki anonimowe wymagają podania nazwy w celu pozyskania uchwytu (wskaźnika),
c) dostarczają uchwyty do zapisu i odczytu operacji na plikach,
b) identyfikowane są w systemie Linux poprzez funkcję generującą identyfikator ftok(),
Pytanie 25
Prawdą jest, że:
d) pamięć dzielona jest identyfikowana jedynie jako lokalny wskaźnik.
a) Pamięć dzielona nie posiada mechanizmów synchronizacji dostępu do danych
b) Pamięć dzielona pozwala na komunikację asynchroniczną,
c) pamięć dzielona polega na utworzeniu kopii obiektu pamięci dzielonej w każdym podłączającym się do niej procesie
Pytanie 26
Prawdą jest, że:
d) pamięć dzielona tworzona jest w momencie podłączenia się drugiego procesu dokonującego wymiany danych, w przypadku czytania z pustej pamięci generowany jest odpowiedni sygnał (Linux).
synchronizację międzyprocesową pamięci dzielonej można przeprowadzić przy pomocy semafora anonimowego,
c) dostęp do obiektu pamięci dzielonej mogą uzyskać co najwyżej dwa osobne procesy (nadawca i odbiorca),
a) Instrukcje atomowe pozwalają na synchronizowany dostęp do zmiennych w obrębie pamięci dzielonej
Pytanie 27
Prawdą jest, że:
c) pamięć dzielona jest optymalnym rozwiązaniem do przekazywania pojedynczych zmiennych,
d) pamięć dzielona jest optymalnym rozwiązaniem do przekazywania ciągu wiadomości.
b) aby uzyskać dostęp do spójnych danych w pamięci dzielonej, trzeba wykorzystywać globalne obiekty synchronizujące, M
a) dane w pamięci dzielonej formowane są jako paczki,
Pytanie 28
Prawdą jest, że:
a) potoki nazwane występują w systemie Linux,
c) potoki nazwane zawsze posiadają osobnego odbiorcę i osobnego nadawcę (dwa różne procesy),
b) potoki nazwane pozwalają na komunikację opartą o powiadomienia o nadejściu wiadomości,
d) komunikacja w potokach nazwanych może odbywać się obustronnie.
Pytanie 29
Prawdą jest, że potoki nazwane:
b) pozwalają na komunikację jedynie jednostronną,
c) pozwalają na komunikację zorientowaną na wiadomości,
d) pozwalają na informowanie odbiorcy o nadejściu danych.
a) nie występują w systemie Windows NT,
Pytanie 30
Prawdą jest, że potoki nazwane:
d) realizują przepływ danych ograniczony do przestrzeni adresowej jednego procesu.
a) pozwalają na komunikację procesów niespokrewnionych,
b) pozwalają na komunikację procesów tylko spokrewnionych,
c) pozwalają na wysyłanie danych od wielu procesów do wielu procesów jednym obiektem potoku,
Pytanie 31
Prawdą jest, że:
b) strumieniowe bazy danych oparte są o strumienie tabel danych,
c) bazy analityczne mogą służyć do magazynowania nadchodzących danych,
d) bazy relacyjno-obiektowe pozwalają na definicję struktur. M
a) obiektowe bazy danych pozwalają na przechowywanie danych w tabelach,
Pytanie 32
Prawdą jest, że:
c) bazy relacyjne wymagają przeszukiwania całej tabeli,
d) bazy temporalne to rodzaj baz służących do przechowywania danych tymczasowych. M
a) zapytanie w strumieniowych bazach danych może obejmować stale wydłużający się okres,
b) bazy relacyjno-obiektowe mają rozszerzenia GIS,
Pytanie 33
Prawdą jest, że:
c) hurtownie danych to rodzaj baz, gdzie tworzone są kolejne wirtualne instancje baz danych,
d) relacyjne bazy danych oparte są o koncepcję zbiorów encji.
b) obiektowe bazy danych mają ustandaryzowany protokół dostępu (język),
a) aktywne bazy danych czekają na operacje zadane przez użytkownika,
Pytanie 34
Prawdą jest, że w przypadku relacyjnych baz danych:
c) dane relacji to zbiór wszystkich krotek,
b) schemat relacji to nazwa relacji i zbiór krotek,
d) krotka to atomowa dana, jaką zawiera tabela
a) atrybut to zbiór encji o tych samych wartościach,
Pytanie 35
Prawdą jest, że w przypadku relacyjnych baz danych:
a) krotki muszą mieć unikalne dane,
b) krotki nie mają nadanej kolejności,
c) atrybuty dwóch różnych krotek w tej samej tabeli różnią się,
d) klucz pozwala nadać krotkom jedną wartość.
Pytanie 36
Prawdą jest, że w przypadku relacyjnych baz danych:
d) klucz służy do wskazania najważniejszego atrybutu.
b) zbiór encji ma przypisaną kolejność poszczególnych encji,
a) zbiory encji słabych nie maja własnych atrybutów,
c) zbiór encji ma ten sam zbiór atrybutów,
Pytanie 37
Prawdą jest, że w przypadku relacyjnych baz danych:
b) w związku 1:N krotka tabeli po stronie 1 jest podrzędna w stosunku do krotki po stronie N,
c) związki M:N nie są naturalnymi związkami występującymi w opisie świata,
związek N:1 nie różni się od związku 1:N schematów bazy.
a) w związku 1:1 obie łączone krotki dwóch tabel są równorzędne,
Pytanie 38
Prawdą jest, że w przypadku relacyjnych baz danych:
d) odwzorowanie jest częściowe, jeśli każda encja zbioru źródłowego ma swój obraz
a) związek M:N nie zawsze musi być dekomponowany,
c) dekompozycja M:N polega na wprowadzeniu dwóch nowych tabel w miejsce tabel po stronie M i N,
b) w związku 1:1 jedna z tabel jest podrzędna, a druga nadrzędna M
Pytanie 39
Prawdą jest, że w przypadku relacyjnych baz danych:
b) odwzorowanie jest całkowite, jeśli istnieją z zbiorze źródłowym encje bez obrazu
d) związek encji wymuszający integralność można ustalać dla dowolnych tabel posiadających dane.
a) dekompozycja M:N polega na dodaniu nowej tabeli łączącej pośrednio dwie w związku ? M:N
c) odwzorowanie 1:1 nie wyróżnia tabeli nadrzędnej,
Pytanie 40
Dana jest relacja Lekarz (pesel (identyfikator), imię, nazwisko), Pacjent (pesel (identyfikator), imię, nazwisko) opisująca fragment bazy danych przychodni
4.1 Prawdą jest, że:
c) dekompozycja zależności do postaci relacyjnej bazy danych da w rezultacie 3 relacje
a) dekompozycja zależności do postaci relacyjnej bazy danych da w rezultacie 1 relacje opisującą wizyty
b) dekompozycja zależności do postaci relacyjnej bazy danych da w rezultacie 2 relacje
d) dekompozycja zależności do postaci relacyjnej bazy danych da w rezultacie 4 relacje, gdyż należy przypisać pacjenta do lekarza oraz dodać informację o wizycie
Pytanie 41
Dana jest relacja Lekarz (pesel (identyfikator), imię, nazwisko), Pacjent (pesel (identyfikator), imię, nazwisko) opisująca fragment bazy danych przychodni
Prawdą jest, że baza danych, która powstanie z dekompozycji relacji M:N
a) z definicji musi spełniać 3NF
d) może prowadzić do redundancji danych
c) nie posiada atrybutów wielowartościowych
b) jest pozbawiona zależności wielofuncyjnych M
Pytanie 42
Dana jest relacja Lekarz (pesel (identyfikator), imię, nazwisko), Pacjent (pesel (identyfikator), imię, nazwisko) opisująca fragment bazy danych przychodni
Związek binarny M:N obustronnie opcjonalny między encjami A i B oznacza, że:
d) nie występuje w rzeczywistości
b) jedno wystąpienie encji A może wchodzić w związek z jednym wystąpieniem encji B
a) jedno wystąpienie encji A może wchodzić w związek z dokładnie jednym wystąpieniem encji B
c) wiele wystąpień encji A musi wchodzić w związek z co najmniej jednym wystąpieniem encji B
Pytanie 43
Prawdą jest, że w tabelach zdenormalizowanych:
anomalia redundancji prowadzi do wielokrotnego występowania tej samej wartości w jednej krotce,
anomalia błędu modyfikacji oznacza niemożność modyfikacji krotki bez modyfikacji jej atrybutów objętych kluczem,
anomalia błędu usunięcia oznacza niemożność usunięcia krotki, której wartość jest objęta kluczem.
anomalia wstawiania oznacza niemożność wprowadzenia krotki bez wszystkich ważnych, kluczowanych atrybutów,
Pytanie 44
Prawdą jest, że w tabelach zdenormalizowanych:
d) anomalia wstawiania dotyczy sytuacji, gdy powtarza się dana w atrybucie kluczowym lub unikalnym.
b) anomalia błędu usunięcia polega na utracie części atrybutów wraz z usuwaniem krotki, która te atrybuty opisuje,
a) anomalia błędu modyfikacji polega na problemie spójnej aktualizacji danych wszystkich objętych nią krotek,
c) anomalia redundancji wiąże się z powtarzaniem się kolumn w konstrukcji tabeli zdenormalizowanej,
Pytanie 45
Prawdą jest, że w tabelach zdenormalizowanych:
b) anomalia modyfikacji wiąże się z problemem modyfikacji atrybutów tworzących liczne kolumny klucza złożonego,
d) anomalia usunięcia polega na niemożności usunięcia krotki z wartością klucza głównego, do której odwołują się krotki klucza obcego innej tabeli.
c) anomalia redundancji może wpływać na wydajność zapisu danych na nośnikach bazy danych,
a) anomalia błędu wstawiania prowadzi do spadku wydajności operacji odczytu,
Pytanie 46
Prawdą jest, że:
a) dla każdej tabeli można wskazać nietrywialną zależność funkcyjną, która obejmuje klucz główny, występujący po obu stronach opisu zależności,
d) zależność wielowartościowa to zależność, w której danej wartości po stronie lewej przypisuje się zbiór wartości po stronie prawej.
c) zależność funkcyjna jest trywialna, gdy atrybuty po lewej stronie zawierają się w atrybutach po prawej stronie,
b) pełna zależność funkcyjna nie występuje wówczas, gdy pewien klucz jednoznacznie identyfikuje pewne wartości niekluczowe.
Pytanie 47
Prawdą jest, że:
c) każda tabela posiadająca klucz posiada także co najmniej jedną nietrywialną zależność funkcyjną, w której atrybut klucza jest po obu stronach w opisie zależności,
b) częściowa zależność funkcyjna ma miejsce, gdy pewien podklucz jednoznacznie identyfikuje pewne wartości niekluczowe
a) zależność funkcyjna nietrywialna oznacza, że każdej kolumnie po stronie prawej odpowiada kolumna po stronie lewej w opisie zależności,
d) zależność wielowartościowa to zależność, w której zbiorowi wartości po stronie lewej przypisuje się wartość po stronie prawej,
Pytanie 48
Prawdą jest, że:
b) zależność funkcyjna jest całkowicie nietrywialna, jeśli po lewej stronie opisu zależności jest tylko klucz główny,
a) zależność wielowartościowa to zależność, w której danej wartości po stronie lewej przypisuje się zbiór wartości po stronie prawej,
c) zależność wielowartościowa to zależność, w której zbiorowi wartości po stronie lewej przypisuje się zbiór wartości po stronie prawej,
d) dla każdej tabeli można wskazać nietrywialną zależność funkcyjną, która obejmuje klucz obcy, występujący po obu stronach opisu zależności,
Pytanie 49
Prawdą jest, że relacja w 1NF:
b) jest także w postaciach normalnych 2NF, 3NF i BCNF,
c) może zawierać w sobie krotki opisujące pojedyncze elementy listy,
d) może zawierać krotki posiadające jako atrybuty agregaty danych.
a) jest także w postaciach normalnych 2NF i 3NF,
Pytanie 50
Prawdą jest, że relacja w 1NF:
c) może zawierać listy wartości atomowych,
b) jest także w postaciach normalnych 2NF, 3NF, 4NF i 5NF,
d) może zawierać tablice wartości atomowych.
a) musi być w postaci 1NF, żeby móc być w postaciach normalnych 2NF, 3NF, 4NF i 5NF
Pytanie 51
Prawdą jest, że relacja w 1NF:
c) elementem krotki może być dowolna struktura danych złożona ze zdefiniowanych w bazie (np. poprzez SQL) danych atomowych,
a) może zawierać struktury skonstruowane tylko przy pomocy wartości atomowych,
b) postać normalna 1NF jest wymagana dla każdej bazy relacyjno-obiektowej,
d) tabela może zawierać atrybuty tylko z listy przyjętych wartości atomowych, dla których istnieją operatory.
Pytanie 52
Prawdą dla drugiej postaci normalnej 2NF jest:
a) relacja X jest w postaci 2NF jeśli jest 1NF i nie zawiera pełnych zależności funkcyjnych,
d) zależności przechodnie występują tylko między atrybutami wchodzącymi w skład klucza złożonego.
c) nie mogą istnieć zależności pomiędzy atrybutami kluczowymi,
b) relacja X jest w postaci 2NF jeśli jest 1NF i nie zawiera częściowych zależności funkcyjnych,
Pytanie 53
Prawdą dla drugiej postaci normalnej 2NF jest:
c) każdy podklucz określa wszystkie niekluczowe atrybuty,
b) pewien podklucz określa wszystkie niekluczowe atrybuty,
a) klucz określa wszystkie niekluczowe atrybuty,
d) relacja w 2NF nie ma zależności przechodnich,
Pytanie 54
Prawdą jest, że relacja w drugiej postaci normalnej 2NF:
c) nie ma nietrywialnych zależności funkcyjnych, w których podklucz jest po lewej stronie
d) nie ma zależności funkcyjnych między atrybutami niekluczowymi.
a) nie musi być postaci 1NF, za to 1NF musi być postaci 2NF,
b) musi mieć klucz opisujący wszystkie zależności między atrybutami niekluczowymi,
Pytanie 55
Relacja będąca w 3NF:
pozbawiona jest anomalii związanej ze wstawianiem danych
jest relacją, w której wszystkie wtórne atrybuty zależą tylko od super-klucza
nie posiada powtarzających się informacji
pozbawiona jest anomalii związanej z usuwaniem danych
Pytanie 56
Prawdą jest, że relacja, która spełnia 3NF:
d) umożliwia definiowanie atrybutów wtórnych częściowo funkcyjnie zależnych od klucza podstawowego relacji
c) gwarantuje, że wartości wszystkich atrybutów są atomowe
a) spełnia również BCNF
b) powstała poprzez usunięcie zależności wielowartościowych
Pytanie 57
Prawdą jest, że:
b) każdy schemat tabeli można zdekomponować do postaci mniejszych schematów zgodnych z 3NF bez utraty informacji
d) każdy schemat tabeli można zdekomponować do postaci mniejszych schematów zgodnych z 3NF bez utraty informacji lub bez utraty zależności
a) każdy schemat tabeli można zdekomponować do postaci mniejszych schematów zgodnych z 3NF bez utraty informacji i bez utraty zależności
c) każdy schemat tabeli można zdekomponować do postaci mniejszych schematów zgodnych z 3NF bez utraty zależności
Pytanie 58
Prawdą jest, że:
Relacja będąca w BCNF nie posiada zależności funkcyjnych
Relacja będąca w BCNF nie posiada zależności wielowartościowych
Każdą relację można bez utraty informacji zdekomponować do postaci Boyce-Codda
Relacja będąca w BCNF nie musi spełniać 3NF
Pytanie 59
Prawdą jest, że:
d) Postać BCNF jest mniej restrykcyjna niż 3NF
c) Każdy schemat tabeli można zdekomponować do postaci mniejszych schematów zgodnych z BCNF bez utraty zależności
a) Dekompozycja do postaci BCNF usuwa całkowicie anomalie powstające przy usuwaniu danych
b) Jeżeli relacja spełnia założenia BCNF to nie występuje w niej redundancja
Pytanie 60
Prawdą jest, że:
b) relacja nie jest odporna jest na anomalie powstałe podczas dodawania danych
d) dla każdej zależności funkcyjnej X -&rt; A występującej w relacji X jest nadkluczem schematu R.
a) dekompozycja do postaci BCNF powoduje, że relacja posiada tylko klucz prosty
c) dekompozycja do postaci BCNF powoduje, że relacja posiada tylko klucz złożony
Pytanie 61
Przekształceniem geometrycznym nie jest:
a) obrót obrazu,
b) przesunięcie obrazu,
c) binaryzacja obrazu,
d) zmiana wielkości obrazu.
Pytanie 62
Rozpatrujemy następujący obraz szary:
55 56 57
Jaki zmieni się ten obraz po operacji rozszerzenia zakresu histogramu (zakres poziomów szarości od 0 do 255)?
0 255 56
0 255 127
55 56 57
0 57 255
Pytanie 63
Rozpatrujemy obraz szary
15 45 22
20 48 35
13 12 56
Jaki będzie wynik binaryzacji tego obrazu z dolnym progiem wynoszącym 30?
101/110/ 110
010/011/001
0 15 0/0 18 5/0 0 26
45 75 55/50 78 65/43 42 26
Pytanie 64
Macierz konwolucji:
111
121
111
Jest wykorzystywana do:
c) Filtracji dolnoprzepustowej mającej na celu minimalizacje rozmycia konturów obiektów,
b) Filtracji górnoprzepustowej mającej na celu wykrycie punktów izolowanych,
a) Filtracji górnoprzepustowej mającej na celu wykrycie krawędzi,
d) Filtracji dolnoprzepustowej mającej na celu znaczne rozmycie konturów obiektów.
Pytanie 65
Laplasjan służy do:
d) wykrywania narożników obiektów.
b) wykrywania poziomych i pionowych konturów obiektów,
c) wykrywania wszystkich konturów obiektów,
a) usuwania szumów w obrazie,
Pytanie 66
W wyniku filtracji obrazu Ob1 otrzymano obraz Ob2 (obraz przed normalizacją):
Jakiego filtru użyto w tej operacji?:
d) Prewitta.
a) uśredniającego,
c) Robertsa,
b) gradientu morfologicznego,
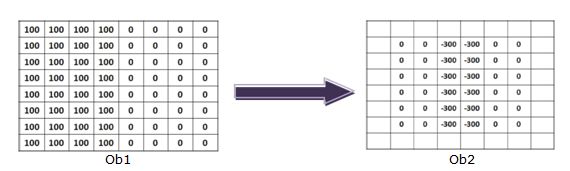
Pytanie 67
Rozpatrujemy przekształcenia morfologiczne: erozja, dylatacja, otwarcie, zamknięcie (przy wykorzystaniu tego samego elementu strukturalnego, na tym samym obrazie wejściowym). Jakie związki zachodzą między wynikami tych operacji?
d) dylatacja ≥ erozja ≥ obraz wejściowy ≥ zamknięcie ≥ otwarcie
a) obraz wejściowy ≥ erozja ≥ dylatacja ≥ otwarcie ≥ zamknięcie
c) zamknięcie ≥ otwarcie ≥ obraz wejściowy ≥ dylatacja ≥ erozja
b) dylatacja ≥ zamknięcie ≥ obraz wejściowy ≥ otwarcie ≥ erozja
Pytanie 68
Rozpatrujemy obraz:
oraz element strukturalny
W wyniku operacji Hit-or-Miss, dla piksela zaznaczonego czarną obwódką, otrzymamy wartość:
4
5
1
0

Pytanie 69
Które stwierdzenie nie jest prawdziwe?
b) Jeżeli na obrazie wykonamy erozję, a następnie na otrzymanym wyniku wykonamy kolejną erozję takim samym elementem strukturalnym, to w rezultacie drugiej operacji na otrzymamy żadnych zmian.
a) Erozję obrazu można otrzymać wykonując dylatację dopełnienia obrazu a następnie wykonując dopełnienie obrazu będącego wynikiem tej operacji.
d) Erozję wykorzystuje się do otrzymania funkcji dystansu
c) Jeżeli punkt centralny należy do elementu strukturalnego, to wynik erozji obrazu binarnego zawiera się w obrazie przed erozją,
Pytanie 70
Rozpatrujemy następujący obraz:
Jaką wartość będzie miał piksel otoczony ciemną obwódką po operacji otwarcia obrazu elementem strukturalnym w kształcie kwadratu o rozmiarze 3x3, z punktem centralnym w jego środku.
7
3
1
5
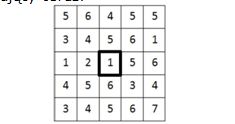
Pytanie 71
Zamknięcie służy m.in. do:
a) usunięcia otworów w obiektach,
d) wykrycia konturów obiektów.
b) usunięcia małych obiektów,
c) rozłączenia obiektów leżących blisko siebie,
Pytanie 72
Jeżeli od obrazu odejmiemy obraz będący wynikiem filtracji tego obrazu otwarciem morfologicznym wykorzystującym stosunkowo duży element strukturalny, to:
b) otrzymamy obraz gradientu morfologicznego,
c) otrzymamy obraz ze wzmocnionymi krawędziami,
d) usuniemy z obrazu efekt nierównomiernego oświetlenia.
a) otrzymamy obraz uśredniony, pozbawiony szumów,
Pytanie 73
Po transformacji Fouriera otrzymano piksel o wartości 3+4i. Jaka jest wartość modułu tego piksela?
3
6
4
5
Pytanie 74
W wyniku transformacji Fouriera obrazu Ob1 otrzymano obraz, na którym wycięto składowe odpowiadające za niskie częstotliwości(jak na obrazie Ob2).
Jak będzie wyglądał rezultat odwrotnej transformacji Fouriera obrazu Ob2 ?
b
a
c
d

Pytanie 75
) Na obrazie szarym (poziomy szarości z przedziału 0-255) przeprowadzono transformację Fouriera, wymnożono f-obraz przez charakterystykę filtru oraz wykonano na wyniku mnożenia odwrotną transformację Fouriera. W rezultacie otrzymano:
c) przefiltrowany obraz , dla którego poziomy szarości pikseli mogą być liczbami zespolonymi,
b) przefiltrowany obraz, dla którego poziomy szarości pikseli należą do przedziału [0, 255],
a) obraz binarny, na którym otrzymano posegmentowane obrazy
d) obraz skompresowany (algorytmem JPEG).
Pytanie 76
Celem segmentacji jest:
c) połączenie kilku zdjęć w jeden większy obraz,
b) podział obrazu na rozdzielone od siebie obiekty,
a) usunięcie z obrazu szumów,
d) wykrycie na obrazie prostoliniowych segmentów
Pytanie 77
Przekształcenie watershed często wykorzystywane jest do:
d) wyliczania szkieletu obiektów.
b) podziału obiektów połączonych ze sobą,
a) eliminacji niewielkich obiektów,
c) zliczania obiektów które nie stykają się z brzegiem obrazu,
Pytanie 78
Przyłączanie do obszaru sąsiednich pikseli (lub obszarów) posiadających podobne cechy (tj. spełniających pewne kryterium jednorodności), to idea segmentacji:
c) przez podział,
d) przez rozrost.
a) z użyciem watershed,
b) z wykorzystaniem binaryzacji automatycznej,
Pytanie 79
Wykorzystywana w pomiarze długości obwodów obiektów formuła Croftona polega na:
a) zliczaniu punktów brzegowych obiektu z uwzględnieniem wag,
c) pomiarze długości rzutów obiektu w 4 kierunkach,
d) wyliczeniu średniej z ilości pikseli po wewnętrznej i zewnętrznej stronie obwodu.
b) przybliżaniu kształtu obiektu odpowiednim wielokątem,
Pytanie 80
Który z wyników najdokładniej podaje liczbę obiektów przypadająca na poniższe pole?
4.5
7
5.5
4

Pytanie 81
) Obiekt składa się z 1000 pikseli. Współczynnik kalibracji informuje nas, że długość 1 piksela to 2 mikrometry. Pracujemy w siatce kwadratowej. Rzeczywiste pole powierzchni obiektu to:
c) 4000 mikrometrów kwadratowych,
b) 2000 mikrometrów kwadratowych
a) 1000 mikrometrów kwadratowych,
d) 500 mikrometrów kwadratowych.
Pytanie 82
W teorii rozpoznawania obrazów wektorem cech jest:
d) zbiór poprawnych klasyfikacji dla rozpoznawanych obiektów.
c) zbiór parametrów opisujących rozpoznawany obiekt,
b) zbiór obiektów dla których podany jest poprawny wynik rozpoznania,
a) metoda wykorzystywana w rozpoznawaniu,
Pytanie 83
Metoda k-najbliższych sąsiadów (kNN) wymaga przed podjęciem decyzji o klasyfikacji:
c) otoczeniu wszystkich elementów ciągu uczącego kulami o promieniu równym k,
b) wyszukania k najbliższych elementów ciągu uczącego,
a) wyznaczenia odległości do środków każdej z k najbliższych klas,
d) wyznaczenia odległości do wszystkich elementów k-tej klasy w ciągu uczącym.
Pytanie 84
Przestrzeń cech definiują dwa parametry: średni poziom szarości ziarna – stosunek minimalnej średnica Fereta do maksymalnej średnica Fereta.
Ziarno, którego wektor cech na wykresie oznaczony jest gwiazdką jest:
d) Okrągłe i ciemne
a) Wydłużone i jasne,
b) Wydłużone i ciemne,
c) Okrągłe i jasne,
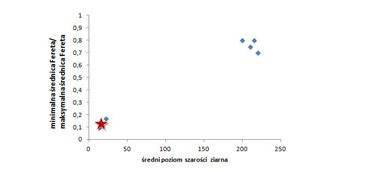
Pytanie 85
Do wydruku polskiej flagi (idealna biel i idealna czerwień) wykorzystywane są następujące tusze (zaznacz odpowiednią ich ilość):
b) C oraz K.
d) C oraz M oraz Y
a) M oraz Y,
c) C oraz Y,
Pytanie 86
Składowa R polskiej flagi (idealna biel i idealna czerwień) ma postać (na rysunkach poniżej: czarny – poziom szarości 0; biały – poziom szarości 255):
c
d
a
b

Pytanie 87
Piksel w modelu RGB ma barwę kodowaną jako: R=200, G=150, B=100 (stopnie szarości znajdują się w przedziale 0-255). Prawdą jest, że dla tego piksela, w modelu barw CMY:
a. Składowa C ma wartość 100,
b. Składowa M ma wartość 155,
d. Składowa Y ma wartość 155,
c. Składowa C ma wartość 205,
Pytanie 88
Jeżeli w kodowaniu JPEG zmniejszymy wartości w tablicy kwantyzacji to w rezultacie:
a) zwiększymy rozmiar pliku z obrazem,
b) zmniejszymy rozmiar pliku z obrazem,
c) pogorszymy jakość kompresji,
d) zmniejszymy wielkość obrazu.
Pytanie 89
Ramki I w kompresji MPEG mają za zadanie:
c) przechowywać te fragmenty klatki obrazu, które zmieniły się w stosunku do klatki poprzedniej,
d) przechowywać te fragmenty klatki obrazu, które zmieniły się w stosunku do klatki poprzedniej bądź następnej.
b) przechowywać pełne, skompresowane algorytmem JPEG, klatki obrazu,
a) przechowywać pełne, nieskompresowane klatki obrazu,
Pytanie 90
Ustawienie zygzakowate w algorytmie JPEG stosowane jest w celu:
d) przygotowanie danych do kwantyzacji.
c) przygotowania do stratnej kompresji przy wykorzystaniu transformacji falkowej,
b) przygotowanie do stratnej kompresji przy wykorzystaniu transformacji kosinusowej,
a) przygotowania do kompresji bezstratnej (m.in. algorytmami RLE i Huffmana),
Pytanie 91
Jaki efekt daje poniższy fragment kodu?
int main( int argc, char** argv )
{
. . .
FILE* pHandle = fopen( *++argv, ”rb” ) );
. . . .
}
b) Błąd kompilacji
d) Otwiera plik binarny do odczytu, którego nazwa jest przekazana do funkcji main jako drugi argument linii komend
c) Otwiera plik binarny do odczytu, którego nazwa jest identyczna jak nazwa programu i jest przekazana do funkcji main
a) Otwiera plik binarny do zapisu, którego nazwa jest którego nazwa jest przekazana do funkcji main jako drugi argument linii komend
Pytanie 92
Jaki efekt daje poniższy fragment kodu : if( ( pHandle = fopen( argv[1], ”wb” ) ) )
{ int x = 12; int* p = &x;
fwrite( *(&p), sizeof( int ), 1, pHandle );
. . . . .
}
a) Zostaną zapisane do pliku dwa znaki reprezentujące cyfry wartości zmiennej x
d) Błąd kompilacji
b) Zostanie zapisane do pliku binarnie liczba 12 w postaci takiej ilości bajtów ile wynosi reprezentacja zmiennej x
c) Błąd wykonania
Pytanie 93
Wywołanie funkcji fclose() z parametrem, który jest uchwytem pliku:
d) Jest konieczne w przypadku zapisu do pliku, aby został wyczyszczony bufor związany z uchwytem pliku (wykonywana operacja fflush() przed zamknięciem pliku)
b) Nie jest konieczne dla poprawnego działania programu wykonującego operacje odczytu i zapisu do pliku
c) Jest konieczne w przypadku zapisu i odczytu pliku, aby plik wejściowy i wyjściowy nie zostały uszkodzone (wykonana operacja _commit() ) .
a) Jest konieczne w celu poprawnego stworzenia tylko pliku tekstowego otwartego do zapisu
Pytanie 94
Funkcja standardowa realloc( p, nBajts ) wykonuje:
a) Zwraca wskaźnik do typu void do realokowanego bloku pamięci. W przypadku gdy wskaźnik p jest pusty to działa jak funkcja malloc()
d) Przenosi blok pamięci wskazywany przez p w inne miejsce pamięci operacyjnej i zwraca wskaźnik do realokowanego bloku.
b) Zwraca wskaźnik typu void do realokowanego bloku pamięci. W przypadku gdy wskaźnik p jest pusty to działa jak funkcja calloc()
c) Realokuje blok pamięci wskazywany przez wskaźnik p i zwraca 1 w przypadku powodzenia lub 0 w przypadku nie powodzenia. W przypadku gdy wskaźnik p jest pusty to działa jak funkcja malloc()
Pytanie 95
Która instrukcja alokuje pamięć na dynamiczną tablice i ją zeruje?
d) int* tab = calloc( 1000 * sizeof( short int ) );
c) int x = 12; int* tab = (int*)malloc( 1000 * sizeof( x ) );
b) int x = 12; int* tab = (int*)calloc( 1000 * sizeof( x ) );
a) int* tab = (int*)malloc( 1000 );
Pytanie 96
Jaki będzie efekt wykonania fragmentu kodu?
memset( pTab, 1, 100*sizeof( int ) );
a) Wypełni dynamiczną tablicę 100-tu elementową wskazywaną przez pTab wartościami 1
c) Błąd wykonania
d) Wypełni każdy bajt dynamicznego bloku wskazywanego przez pTab wartością 1
b) Wypełni 100 bajtów wskazywanych przez wskaźnik pTab wartością 1
Pytanie 97
Aby skompilować kod do użycia jako bibliotekę dynamiczną (utworzenie relokowalnego kodu) należy go skompilować:
d) gcc -fpic -Wall –c *.c
b) gcc -fPIC -Wall –c *.c
a) gcc -lib -Wall –c *.c
c) gcc -shared -Wall –c *.c
Pytanie 98
Aby stworzyć bibliotekę libtest mając skompilowany kod relokowalny należy?
d) gcc -static -Wl,-soname,libtest.so.1 -o libtest.so.1.0 *.o
a) gcc -Wl,-soname,libtest.so.1 -o libtest.so.1.0 *.o
b) gcc -shared -Wl,-soname,libtest.so.1 -o libtest.so.1.0 *.o
c) gcc -shared -Wl, libtest.so.1.0 *.o
Pytanie 99
Załadowanie biblioteki dynamicznej podczas wykonania programu wykonuje się funkcją ?
b) dllopen( ”./libtest.so.1.0” )
a) dlsym(”./libtest.so.1.0” );
d) dlload(”./libtest.so.1.0” )
c) dlopen(”./libtest.so.1.0” )
Pytanie 100
Aby nie wykonywać optymalizacji kodu kompilatorem gcc należy użyć opcji
a) –O3
c) –O0
d) -Os
b) -O
Pytanie 101
Poziom optymalizacji, w którym kompilator będzie próbował zwiększyć wydajność kodu za cenę jego rozmiaru oraz czasu kompilacji
c) Poziom pierwszy (-O1) M
d) domyślny
a) Poziom 2 (-O2)
b) Poziom trzeci (-O3)
Pytanie 102
Kompilator GCC przeprowadza najpierw:?
c) optymalizację niezależną od architektury, a następnie zależną od architektury
a) optymalizację określoną przez użytkownika, optymalizację kodu pod konkretny procesor lub nawet model procesora a potem niezależną od architektury.
b) optymalizację zależną, a następnie niezależną od architektury
d) optymalizację niezależną od architektury, a następnie,jeśli użytkownik sobie tego zażyczy, optymalizację kodu pod konkretny procesor lub nawet model procesora
Pytanie 103
1 Dany jest fragment kodu
class K {
double D;
...
};
...
int main() {
/*1*/ double K::* wd;
/*2*/ wd = & K::D;
}
Jak zareaguje kompilator języka C++ przetwarzając kod z linii oznaczonych /*1*/ i /*2*/?
a) Stwierdzi błąd składni w linii /*1*/ (niepoprawna konstrukcja).
b) Stwierdzi błąd w linii /*2*/: nie można znaleźć adresu pola, bez podania instancji klasy K.
c) Uzna obie linie za poprawne składniowo, ale zgłosi błąd związany z naruszeniem reguł dostępu
Kod jest całkowicie poprawny.
Pytanie 104
Dany jest fragment kodu
class K {
public:
double D;
...
};
...
int main ( )
/*1*/ double K::* wd;
/*2*/ wd = NULL;
}
Jak zareaguje kompilator języka C++ przetwarzając kod z linii oznaczonych /*1*/ i /*2*/?
d) Zaakceptuje linię /*1*/, ale w linii /*2*/ odmów przypisania wskaźnikowi do składowej wartości NULL.
b) Stwierdzi błąd składni w linii /*1*/ (niepoprawna konstrukcja).
c) Uzna obie linie za poprawne składniowo, ale zgłosi błąd związany z naruszeniem reguł dostępu.
a) Kod jest całkowicie poprawny.
Pytanie 105
Dany jest fragment kodu
class K {
public :
double D;
...
};
...
int main() {
K obj;
/*1*/ double K::* wd = & K::D;
/*2*/ obj-&rt;*wd = 3.1415;
}
Czy można wykonać operację z linii oznaczonej jako /*2*/? Jeżeli tak, to jaka jest jej semantyka?
d) W linii /*2*/ jest błąd składni, uniemożliwiający kompilację
b) Program da się skompilować, ale operacja z linii /*1*/ uniemożliwi przejście do linii /*2*/.
c) Wartość pola D w obiekcie obj zostanie ustawiona na 3.1415.
a) W linii /*1*/ jest błąd składni, uniemożliwiający kompilację
Pytanie 106
Z definicją… klasy _nie_ wiąże się
określenie wartości pól statycznych,
d) definiowanie rozmiarów i wewnętrznej struktury obiektów.
a) zdefiniowanie nowego typu danych,
c) opis interakcji obiektów danej klasy z otoczeniem, M
Pytanie 107
Zadaniem konstruktora jest
d) logiczne powiązanie metod i pól.
a) przydzielenie pamięci dla obiektu,
c) zintegrowanie obiektu z wywołaniami systemu operacyjnego,
b) nadanie wartości polom obiektu,
Pytanie 108
Uruchomienie destruktora na rzecz danego obiektu powoduje
b) wyczyszczenie obszaru danych zajmowanych przez ten obiekt, M
d) usunięcie informacji o obiekcie z globalnego rejestru obiektów.
c) zwolnienie pamięci zajmowanej przez ten obiekt,
a) wykonanie procedury zdefiniowanej pod stosowną nazwą,
Pytanie 109
Dane są następujące definicje klas i obiektu Obj:
class B {
protecetd :
Complex val;
};
class P : private B {
public :
double val;
};
P Obj;
W obiekcie Obj zmiana zawartości składowej val, odziedziczonego po klasie B (czyli będącej typu Complex) jest:
a) niemożliwa, ze względu na zakres 'protected', M
c) możliwa, jeżeli tylko użyje się wartości odpowiedniego typu (czyli Complex),
b) niemożliwa ze względu na dziedziczenie typu 'private'
d) możliwa, jeżeli użyje się operatora zakresu (tj. '::').
Pytanie 110
W języku C++ dziedzicznie _nie_ obejmuje
a) składowych niestatycznych,
operatora przypisania,
d) wszystkich wymienionych w punktach a-c.
b) składowych o zakresie dostępności 'private',
Pytanie 111
Niech klasa K dziedziczy po klasie SuperK, a Obj jest obiektem typu K. Wywołanie destruktora obiektu Obj w pierwszej kolejnoĹ›ci wykona:
b) wywołanie destruktorów dla poszczególnych składowych odziedziczonych po klasie SuperK,
a) zwolnienie pamięci,
c) wywołanie poszczególnych destruktorów dla niestatycznych składowych własnych (nieodziedziczonych),
d) wywołanie poszczególnych destruktorów dla statycznych składowych własnych (nieodziedziczonych).
Pytanie 112
Dane są deklaracje metod klasy K. Która z nich jest konstruktorem konwertującym?
a) K( const K & );
d) float operator();
c) K( );
b) K( int, float = 0);
Pytanie 113
Który z poniższych konstruktorów _nie_ jest konstruktorem konwertującym?
a) I( float );
c) K( );
b) J( int, float = 0);
d) L( int = 0, int = 0 );
Pytanie 114
Potrzebna jest konwersja z klasy K na klasę Complex. Która z poniższych deklaracji jest poprawną deklaracją operatora konwersji? (Deklaracje dotyczą metod klasy K).
c) operator Complex ( K );
b) Complex operator ();
Complex operator ( K & );
a) operator Complex ();
Pytanie 115
Czy kompilator C++ generuje automatycznie operatory dla nowych typów danych?
d) Nie, poza pięcioma operatorami, w tym: =, &, delete
b) Nie, każdy potrzebny operator musi był zdefiniowany.
c) Tak, ale tylko operatory: =, (), [], -&rt;.
a) Tak, każdy operator posiada swoją wersję domyślną.
Pytanie 116
2 Które z wymienionych operatorów muszą być definiowane jako metody (funkcje wewnętrzne klasy)?
a) operator [],
d) operator !.
b) operator +,
c) operator char *,
Pytanie 117
3 Która z poniższych deklaracji jest niepoprawna.
(Poniższe operatory są definiowane jako funkcje globalne.)
class K;
d) K operator -- ( const K );
b) K operator -- ( const K &, const K & ); M
c) K operator - ( const K & );
a) K operator - ( const K, const K );
Pytanie 118
Klasą abstrakcyjną jest klasa, która
b) zawiera przynajmniej jedną metodę wirtualną,
a) zawiera wyłącznie metody wirtualne,
d) wszystkie metody wirtualne ma zadeklarowane jako czysto wirtualne.
c) posiada przynajmniej jedną metodę czysto wirtualną,
Pytanie 119
Jeżeli w klasie są zdefiniowane metody wirtualne, to
a) nie można utworzyć instancji tej klasy,
b) w klasach potomnych konieczne jest przeładowanie takich metod,
c) w klasach potomnych metody o identycznych sygnaturach także będą wirtualne,
d) metody te mogą być wywoływane jedyne poprzez wskaźnik lub referencję do obiektu.
Pytanie 120
Termin "polimorfizm" (wielopostaciowość) odnosi się do
c) definicji metody,
b) sposobu realizacji wywołania metody,
d) techniki przekazywania obiektów (jako referencje lub wskaźniki).
a) definicji klasy,
Pytanie 121
Jakie są priorytety przerwań obsługiwanych przez procesory z rodziny IA32
c) przerwania obsługiwane są zawsze w kolejności w jakiej zostały zgłoszone
a) przerwanie INT ma najwyższy priorytet
d) jest tylko jedna tablica przerwań, zatem wszystkie przerwania mają ten sam priorytet
b) przerwanie NMI ma najwyższy priorytet
Pytanie 122
Ile różnych przerwań obsługuje procesor rodziny x86
b) po jednym NMI oraz INT,
d) ilość obsługiwanych przerwań zależy od trybu pracy procesora. W trybie rzeczywistym jest to 256 różnych przerwań, natomiast w trybie 32 bitowym ilość ta została zwiększona do 65536.
a) jedno przerwanie NMI i do 256 przerwań typu INT,
c) procesor ma dwie linie przerwań zewnętrznych, ale jest tylko jedna procedura ich obsługi,
Pytanie 123
Czy w procesorach rodziny x86 istnieje możliwość zablokowania przerwań, jeżeli tak to w jaki sposób
a) tak można zablokować przerwanie INT, natomiast nie można blokować przerwań NMI. Zablokowanie/odblokowanie odbywa się przez instrukcję CLI/STI.
d) tak można zablokować zarówno przerwanie INT jak i NMI. Zablokowanie/odblokowanie odbywa się przez instrukcję CLINT/STINT oraz CLNMI/STNMI.
b) tak można zablokować przerwanie NMI, natomiast nie można blokować przerwań INT Zablokowanie/odblokowanie odbywa się przez instrukcję CLI/STI.
c) nie przerwań nie da się zablokować,
Pytanie 124
Model systemów wieloprocesorowych SMP (Symetric Multi Procesor) to
d) model ten to układ procesorów i pamięci tworzących wektory, przy czym dostęp procesorów do układów pamięci odbywa się przez symetryczną macierz połączeń krzyżowych
a) model w którym wszystkie procesory posiadają wspólną pamięć operacyjną i wspólny zestaw urządzeń wejścia/wyjścia.
c) w modelu SMP na każde 2 procesory jest przewidziana oddzielna pamięć oraz zestaw układów I/O. W przypadku większej ilości procesorów łączone są w pary komunikujące się ze sobą szybką magistralą HyperTransport
b) model w którym każdy procesor ma do dyspozycji oddzielną pamięć operacyjną i wydzielone urządzenia wejścia/wyjścia
Pytanie 125
MPP (Massively Parallel Processors) to
b) architektura komputerowa zbudowana z węzłów, gdzie każdy węzeł posiada własny procesor z pamięcią i układami I/O. Węzły połączone są ze sobą najczęściej siecią komputerową.
d) model w którym wszystkie procesory posiadają wspólną pamięć operacyjną i wspólny zestaw urządzeń wejścia/wyjścia.
a) architektura komputera, w której każdy układ (procesor, pamięć, urządzenie I/O) jest, na wzór sieci komputerowej, podłączony szybką magistralą z przełącznikiem. Razem tworzą układ „gwiazdy”, która może być dowolnie rozbudowywana
c) model systemu wieloprocesorowego, w którym każdy procesor ma własny układ pamięci oraz wydzieloną magistralę łączącą go z innymi procesorami (po jednej magistrali na procesor). Model ten był stosowany przez firmę AMD w rozwiązaniach serwerowych. M
Pytanie 126
Architektura SMP i ASMP:
d. SMP stosowany jest w komputerach stosujących procesory wielordzeniowe, natomiast ASMP wykorzystywane jest w systemach stosujących wiele procesorów jednordzeniowych
c. obydwie architektury korzystają z modelu ze wspólną pamięcią, jednak w ASMP każdy procesor ma własną magistralę, natomiast używana pamięć jest wieloportowa.
b. SMP od ASMP różni sposób zarządzania zadaniami i procesami. W SMP wszystkie procesory są równoprawne w przydziale zadań zarówno użytkownika jak i systemowe, natomiast w ASMP jest wydzielony procesor obsługujący wyłącznie zadania systemowe, natomiast pozostałe realizują tylko zadnia użytkowników
a. w SMP wszystkie procesory podłączone są do wspólnej magistrali łączącej je ze wspólną pamięcią, natomiast w ASMP każdy procesor ma własny układ pamięci oraz połączony jest z innymi procesorami wydzieloną magistralą (po jednej na podłączony procesor), M
Pytanie 127
W procesorach IA32, adres logiczny to:
c) adres komórki pamięci, jaki powstaje na skutek działania systemu segmentacji
d) inaczej określenie adres binarny – czyli wartość adresu zapisana w postaci wielobitowej liczby binarnej
b) określenie obszaru pamięci powiązanej funkcjonalnie (logicznie) z przydzieloną jej funkcjonalnością (np. stos, lista jednokierunkowa),
a) adres jaki jest widoczny dla kodu wykonywanego programu,
Pytanie 128
System stronicowania w procesorach IA32 to:
b) system umożliwiający procesorowi adresowanie większego obszaru pamięci niż faktycznie dostępnego. Polega na podziale pamięci na strony, zazwyczaj wielkości 1 MB lub 4 kB.
d) mechanizm umożliwiający współdzielenie pamięci w systemach wieloprocesorowy. Pamieć podzielona jest na obszary (strony) o wielkości 4kB lub 1 MB, i każdy procesor ma przydzielaną oddzielną stronę.
c) system wirtualizacji pamięci polegający na podziale uprawnień dostępu do pamięci przez różne procesy. Każda strona dostępna jest tylko dla wybranego procesu. Wielkość pojedynczej strony jest wielokrotnością 4 kB.
a) system podziału pamięci na strony. Związany jest z budową pamięci DRAM, i polega na podziale całego obszaru pamięci na strony o wielkości wynikającej z wewnętrznej budowy układu. Najczęściej spotykaną wielkością strony pamięci to 4 kB M
Pytanie 129
Adres logiczny w obrębie segmentu, jest przeliczany na liniowy, w procesorach IA32, wg następującego schematu:
b) do adresu logicznego dodawane jest przesunięcie zapisane w deskryptorze segmentu,
c) adres logiczny jest wprost adresem liniowym, jedynie przy dostępie do pamięci sprawdzany jest dozwolony zakres wartości (minimum i maksimum) zapisane w deskryptorze segmentu.
d) numer segmentu jest mnożony przez 16, a następnie do wyniku tego mnożenia dodawany jest adres logiczny. Wynik w postaci liczby 32 bitowej jest adresem liniowym.
a) do adresu logicznego dodawane jest przesuniecie, będące 32 bitowym numerem segmentu,
Pytanie 130
Każdy segment pamięci w architekturze IA32, opisany jest następującymi atrybutami:
c) początek, wielkość, typ wykonywanych zadań (32, 64 bitowe z wirtualizacją lub bez, zadania 16 bitowe)
d) segmenty były używane tylko w trybie rzeczywistym do rozszerzenia obszaru adresowego. Obecnie wykorzystuje się tylko mechanizm stronicowania jako nowocześniejszy.
b) lista uprawnionych procesów mających prawo dostępu, typ segmentu (dane, stos, kod programu) oraz położenie (początek i wielkość segmentu) M
a) początek, wielkość, dozwolone operacje (odczyt, zapis, wykonanie), wymagany poziom uprzywilejowania
Pytanie 131
Tablica deskryptorów w procesorach IA32
b. wykorzystywana jest przez mechanizm stronicowania pamięci. Zawiera informacje o stronach obecnych w pamięci oraz mapę stron zapisanych w pliku stronicowania
d. inaczej nazywana (w trybie rzeczywistym) tablicą przerwań, zawiera wyłącznie adresy procedur obsługi przerwań i wyjątków trybu wirtualnego
c. używana jest przez mechanizm stronicowania. W tablicy zapisywane są deskryptory, czyli struktury w których opisywane są uprawnienia w dostępie do segmentu pamięci oraz jego położenie i wielkość,
a. zawiera deskryptory, czyli struktury opisujące procesy realizowane w systemie operacyjnym. Każdy deskryptor zawiera informacje o położeniu segmentu kodu, danych i stosu oraz zestaw uprawnień w dostępie do pamięci oraz urządzeń I/O M
Pytanie 132
Jednym z głównych zadań systemu segmentacji pamięci w procesorach IA32 jest:
c) podzielenie obszarów pamięci pod względem funkcjonalnych (rozdzielenie kodu od danych), oraz tworzenie podstaw dla mechanizmów ochrony pamięci przydzielanej równolegle działającym procesom,
a) uproszczenie sposobu obliczania adresu fizycznego w dostępie do pamięci RAM
b) zapewnienie większej wydajności i elastyczności w operowaniu dużymi blokami pamięci, np. szybsze działanie funkcji memcpy() w kopiowaniu pomiędzy segmentami.
d) umożliwienie mechanizmom wirtualizacji pamięci szybsze przenoszenie najmniej używanych segmentów do pliku wymiany oraz zwalnianie nieużywanych segmentów.
Pytanie 133
Działanie przetwornika A/C całkującego polega na:
c) porównaniu wartości mierzonego napięcia z napięciem wzorcowym i systematycznym zwiększaniu lub zmniejszaniu napięcia wzorcowego aż do zrównania się obydwu napięć. M
b) cyklicznym ładowaniu i rozładowywaniu kondensatora, przy jednoczesnym zliczaniu impulsów zegarowych. Czas ładowania jest stały i uzależniony jest od pojemności licznika impulsów Nmax. Pomiar polega na zliczaniu impulsów zegarowych podczas rozładowywania kondensatora do wartości 0.
d) eliminowaniu zakłóceń szybkozmiennych z mierzonego napięcia. Przy odpowiednim dobraniu czasu całkowania umożliwia to usuniecie wpływu zakłóceń pochodzących od sieci energetycznych (50 Hz).
a) Numerycznym obliczaniu całki z przebiegu analogowego w całym okresie.
Pytanie 134
Główne cechy przetwornika A/C całkującego to:
a) duża szybkość działania (ponad 1 MS/s) kosztem dokładności pomiarowej (typowo 8 – 10 bitów)
c) możliwość wykonywania pomiarów w bardzo szerokim zakresie wartości przy zachowaniu wysokiej dokładności działania (tzw. automatyczne dopasowanie zakresu pomiarowego)
b) bardzo duża dokładność pomiaru (nawet lepsza niż 0,01%), ale kosztem relatywnie długiego cyklu pomiarowego (kilka – kilkadziesiąt ms)
d) łatwość implementacji w systemie komputerowym, gdyż wynikiem działania przetwornika jest ciąg impulsów o zmiennej częstotliwości i stałej amplitudzie
Pytanie 135
Przetwornik całkujący A/C z tzw. potrójnym całkowaniem
b. jest rozwinięciem układu klasycznego przetwornika całkującego poprzez dodanie dodatkowego obwodu całkującego umożliwiającego skrócenie czasu przetwarzania. 2 obwody pracujące równolegle skracają czas o około połowę
a. jest rozwinięciem układu klasycznego przetwornika całkującego przez zastosowanie dodatkowego cyklu rozładowywania kondensatora mniejszym prądem, a przez to umożliwia zwiększenie dokładności przetwarzania
d. umożliwia poprawienie dokładności przez trzykrotne powtórzenie procedury całkowania. Wartość wynikowa jest uśrednioną wartością z 3 cykli. Eliminuje to wpływ losowych szumów przetwarzania. Dla dalszego poprawienia dokładności (kosztem czasu) można stosować przetworniki z nawet 11 krotnym przetwarzaniem.
c. zawiera 3 obwody całkujące połączone szeregowo. Pozwala to na poprawienie dokładności i szybkości pracy przetwornika kosztem rozbudowania układu.
Pytanie 136
Przetwornik A/C typu Flash
a) zapewnia bardzo krótki czas pomiarowy (nawet 10-8 [s]) kosztem dokładności
b) wymaga stosowania rozbudowanej logiki sterującej i generatorów wartości pseudolosowych, ale umożliwia uzyskania bardzo dużej dokładności (produkowane są przetworniki nawet 24 bitowe)
c) jest używany w systemach laboratoryjnych z powodu dużej odporności na wysokie napięcia wejściowe
d) umożliwia wykonywanie pomiarów napięć stałych lub bardzo wolno zmiennych, zapewniając dużą stabilność pomiarową. Nie nadaje się do pomiarów napięć szybkozmiennych (powyżej 10 Hz).
Pytanie 137
Układ próbkująco-pamiętający
b. jest wykorzystywany w przetwornikach C/A do utrzymywania wartości napięcia wyjściowego w trakcie wpisywania nowej wartości do rejestru wejściowego
a. jest wykorzystywany w przetwornikach A/C jako podstawowy obwód zamieniający wartość analogową na cyfrową
d. spełnia funkcję pomocniczą w przetworniku A/C kompensacyjnym. Porównuje, a następnie podtrzymuje wynik porównania w obwodzie kompensacyjnym.
c. jest to obwód podtrzymujący stałą wartość napięcia na wejściu przetwornika A/C w czasie pojedynczego cyklu przetwarzania jej na wartość cyfrową M
Pytanie 138
Parametry opisujące przetwornik A/C jak rozdzielczość i dokładność to
c. parametry opisujące jakości pomiaru ale w innych jednostkach. Rozdzielczość przetwarzania podaje jaka jest najmniejsza wartość, jaką można zmierzyć przetwornikiem, wyrażona w voltach, natomiast dokładność to to samo tylko wyrażone w procentach maksymalnej wartości zakresu. Przykładowo przetwornik 10 bitowy o zakresie 0 – 5V ma rozdzielczość =5/1024 =4,88mV , natomiast dokładność = 0,0488*100%/0,5 = 0,976% .
d. parametry opisujące jakości pomiaru. Rozdzielczość jest to najmniejsza wartość jaką rozróżnia przetwornik wyrażona w voltach (tzw. kwant). Dokładność jest parametr opisujący maksymalne błędy pomiarowe, zależny zarówno od rozdzielczości jak i liniowości przetwarzania oraz innych błędów przetwarzania.
b. parametry opisujące jakość przetwornika. Dokładność wynika z długości słowa wyjściowego, natomiast rozdzielczość ze stosunku dokładności do wartości mierzonej wyrażonej w procentach. Przykładowo przetwornik 10 bitowy o zakresie 0 – 5V ma dokładność =5/1024 =4,88mV , a przy mierzonej wartości Ux = 0,5V rozdzielczość to = 0,0488*100%/0,5 = 0,976%
a. dokładnie to samo. Opisuje dokładność przetwarzania i wynika bezpośrednio z tego ilu bitowy jest przetwornik. Przykładowo przetwornik 10 bitowy o zakresie 0 – 5V ma dokładność =5/1024 =4,88mV
Pytanie 139
Kryterium Nyquista w przetwarzaniu sygnału analogowego na cyfrowy:
b. maksymalna częstotliwość mierzonego sygnału nie może być większa niż dwukrotność częstotliwości próbkowania
a. mówi, że wartość skuteczna sygnału mierzonego nie może być większa niż połowa maksymalnego napięcia wejściowego
maksymalna częstotliwość mierzonego sygnału nie może być większ niż połowa częstotliwości próbkowania
d. mówi, że wartość szczytowa sygnału mierzonego nie może być większa niż połowa maksymalnego napięcia wejściowego ( )
Pytanie 140
Aby pomiar wartości analogowej był jak najbardziej dokładny należy
a. dobrać zakres pomiarowy tak, aby napięcie mierzone było w dolnym zakresie wartości. Unika się wtedy błędów nieliniowości przetwarzania
c. wykonać pomiar kilkukrotnie na różnych zakresach pomiarowych i wyciągnąć średnią. Minimalizuje się w ten sposób różne błędy związane z przetwarzaniem (między innymi dyskretyzacji, liniowości i przypadkowy)
b. dobrać zakres pomiarowy tak, aby napięcie mierzone było w górnym zakresie wartości. Minimalizuje się wtedy błędy dyskretyzacji.
d. stosować przetwornik A/C z obwodem kompensacyjnym, którego główną cechą jest automatyczne kompensowanie błędów liniowości i nieliniowości przetwornika
Pytanie 141
Przetwornik A/C kompensacyjny
a) wykonuje pomiar przez odjęcie od napięcia mierzonego, napięcia kondensatora ładowanego prądem o stałej wartości. Wynikiem pomiaru jest czas w jakim wynik tego porównania osiągnie wartość 0. Czas ten jest wprost proporcjonalny do mierzonego napięcia.
b) wykonuje pomiar przez porównanie napięcia mierzonego z napięciem odniesienia wytworzonego przez układ oparty o diodę zenera skompensowaną termicznie. Wynikiem pomiaru jest współczynnik wielokrotności napięcia mierzonego względem napięcia odniesienia uzyskiwany z obwodu ujemnego sprzężenia zwrotnego wzmacniacza operacyjnego podnoszącego wartość napięcia odniesienia.
d) jest inną nazwą przetwornika całkującego. Różnica polega na zastosowaniu w miejsce klasycznych kondensatorów diod pojemnościowych umożliwiających sterowanie zmianę pojemności (kompensowanie).
c) zbudowany jest z przetwornika C/A i komparatora. Wartość napięcia tego przetwornika jest cyklicznie zwiększana i porównywana z wejściowym, aż przekroczy wartość napięcia mierzonego. Wynikiem pomiaru jest ostatnia wartość jaka została podana na wejście przetwornika C/A.
Pytanie 142
W modelu TCP/IP istnieje warstwa Aplikacji, która odpowiada warstwom:
a) Aplikacji, Prezentacji i Sesji modelu OSI/ISO,
d) Aplikacji i Łącza danych modelu OSI/ISO,
c) Aplikacji, Prezentacji i Sieciowej modelu OSI/ISO
b) Aplikacji, Sesji i Transportu modelu OSI/ISO,
Pytanie 143
Który z protokołów stosu TCP/IP odpowiada warstwie sieciowej modelu OSI/ISO?
b) Internetu,
d) Dostępu do sieci
a) Transportowy,
c) Aplikacji
Pytanie 144
Która z warstw modelu OSI/ISO korzysta z adresów sprzętowych?
d) Łącza danych
b) Sesji,
c) Prezentacji,
a) Aplikacji,
Pytanie 145
Utworzenie gniazda realizowane jest funkcją:
a) socket,
d) write,
b) listen
c) read,
Pytanie 146
Wynikiem utworzenia gniazda jest:
a) wskaźnik,
b) ścieżka dostępu,
d) informacja o powodzeniu operacji
c) deskryptor,
Pytanie 147
Do obsługi połączenia TCP, utworzone gniazdo być typu:
b) SOCK_DGRAM,
c) SOCK_RAW
a) SOCK_STREAM,
c) SOCK_CONN_DGRAM,
Pytanie 148
Adres protokołu IPv6 zapisany jako FF0C::B1C2, jest rozumiany:
c) jako adres: FF:0C:B1:C2,
d) jako dwa adresy: FF0C oraz B1C2.
b) jako adres: FF0C:FF:FF:FF:FF:FF:B1C2,
a) jako adres: FF0C:0:0:0:0:0:B1C2,
Pytanie 149
Jakiego rodzaju adresu, który występuje w IP4 nie ma w protokole IP6?
a) adresu rozsyłania grupowego (multicast).
b) adresu rozgłaszana (broadcast),
d) adresu pojedynczego węzła.
c) adresu pętli zwrotnej,
Pytanie 150
Długości adresów dla protokołów IP wynoszą:
c) dla IPv4 – 64 bity, dla IPv6 – 128 bity,
b) dla IPv4 – 32 bity, dla IPv6 – 128 bity,
d) dla IPv4 – 32 bity, dla IPv6 – 256 bity.
a) dla IPv4 – 64 bity, dla IPv6 – 256 bity,
Pytanie 151
Stronicowanie na żądanie to:
Podział aplikacji na segmenty danych, kodu oraz stosu i ładowanie ich podczas pierwszego odwołania do danego segmentu
Ładowanie statyczne stron do pamięci operacyjnej przed uruchomieniem programu
Ładowanie strony do pamięci operacyjnej przy pierwszym odwołaniu do tej strony
Podział przestrzeni adresowej na pewną liczbę równych części z żądaniem równości wielkości segmentu i wielkości strony pamięci
Pytanie 152
Mechanizmy synchronizacji procesów to:
sekcje krytyczne, Semafory, kolejki komunikatów, warunkowe sekcje krytyczne
sekcje krytyczne, Semafory, bufor komunikatów, warunkowe sekcje krytyczne, kolejki zdarzeń
sekcje krytyczne, warunkowe sekcje krytyczne, semafory, sygnały
semafory, bufor zdarzeń, sekcje krytyczne, warunkowe sekcje krytyczne, zagnieżdżone sekcje krytyczne
Pytanie 153
Jaka będzie wartość zmiennej c? #define min( x, y ) ( ((x) &rt;= (y)) ? (x) : (y) ) int a = 2; int b = 4; int c
= min( 1, min( a, b ) );
2
4
1
błąd wykonania
Pytanie 154
Proszę wskazać, jakie są różnice między paradygmatami obiektowym (object-based) i obiektowo
zorientowanym (object-oriented):
Obydwa paradygmaty opisują odrębne aspekty, więc nie da się ich porównać
Różnice są niewielkie, i zasadniczo to jest ten sam paradygmat
W paradygmatach tych odmiennie rozumie się pojęcia enkapsulacji i interfejsu.
Tylko w paradygmacie obiektowo zorientowanym występują pojęcia dziedziczenia i wielopostaciowości.
Pytanie 155
Rozpatrujemy obraz szary znormalizowany do przedziału 0-1 i o płaskim histogramie. Dla takiego
obrazu możemy powiedzieć, że:
filtracja laplasjanem o sumie elementów maski 1 powoduje rozmycie obrazu
erozja kwadratowym elementem strukturalnym o boku 10 jest równoznaczna pięciu następującym po sobie erozjom liniowym elementem strukturalnym o rozmiarze dwa
operacja pierwiastka kwadratowego z intensywności spowoduje wzrost kontrastu dla obszaru, gdzie występowały ciemne pikseli w obrazie wejściowym
dyskretna, dwuwymiarowa transformata cosinusowa posiada maksimum w środku obrazu transformaty
Pytanie 156
Porównanie właściwości pamięci RAM: statycznej (SRAM) oraz dynamicznej (DRAM). Główne cechy tych pamięci to:
obecnie zarówno pamięć SRAM jak i DRAM nie są już stosowane i zostały zastąpione znacznie nowocześniejszą konstrukcją opartą o technologię Flash.
pamięć DRAM jest zdecydowanie szybsza i prostsza w budowie od pamięci SRAM, dlatego jest obecnie stosowana w komputerach,
pamięć SRAM jest szybsza od pamięci DRAM, ale znacznie bardziej skomplikowana w budowie,
pamięć DRAM jest rozwinięciem konstrukcji SRAM, np. wyeliminowano konieczność stosowania odświeżania i zastosowano sterowanie synchroniczne,